
Cómo funciona un modelo de lenguaje?
La generación de una respuesta paso a paso

Cuando interactuamos con un modelo de lenguaje, a menudo da la impresión de que estamos hablando con alguien a través de un chat. Por lo menos, eso es lo que intentan las empresas que los ofrecen. Lo que pasa en realidad es algo diferente, más cercano a tirar un dado y encender una bombilla u otra según el número que haya salido que a hablar con otra persona.
Hoy pretendo explicar de forma sencilla cómo funciona este proceso, cómo un modelo parte del texto que escribimos y de alguna manera obtiene otro texto que –mejor o peor– le da respuesta.
Para ello, usaré el siguiente ejemplo, extremadamente simple:
Usuario: Hola, qué tal?
Asistente: Estoy muy bien!
La entrada del modelo
Cuando le mandamos un mensaje a un modelo de lenguaje, no le mandamos únicamente lo que escribimos en el campo de texto. En realidad, eso es únicamente el mensaje del usuario. La entrada del modelo incluye también el mensaje del sistema (system prompt), que incluye metadatos o instrucciones específicas. En nuestro ejemplo, la entrada completa –tomándome algunas licencias para que se entienda mejor– podría ser la siguiente:
<INICIO_DEL_TEXTO> <INICIO_ROL>sistema<FIN_ROL> Fecha de corte de entrenamiento: Diciembre 2024 Fecha de hoy: 8 Junio 2025 Eres un asistente útil. <INICIO_ROL>usuario<FIN_ROL> Hola, qué tal? <INICIO_ROL>asistente<FIN_ROL>
Vayamos por partes. Los marcadores entre <> son palabras reservadas para el modelo, son como los signos de puntuación, y delimitan sus diferentes partes. Aquí vemos una marca de inicio del texto y varias marcas de inicio y fin de rol. Así, la entrada del modelo consta de un mensaje de sistema, un mensaje de usuario y una marca de mensaje de asistente.
El mensaje de sistema aquí incluye algunas fechas útiles e instrucciones genéricas de comportamiento (“Eres un asistente útil”). Este mensaje suele contener otras instrucciones –no necesariamente visibles para nosotros– que las empresas no quieren que veamos, y en algunos casos podemos editar este mensaje. Por ejemplo, podríamos añadir “Habla como un pirata” para intentar forzar esta forma de hablar.
El mensaje de usuario es exactamente lo que hayamos escrito en la caja de texto.
Por último, la entrada termina con una marca de mensaje de asistente. De esta manera, cuando el modelo genere una nueva palabra, lo hará en este entorno.
La tokenización
Irónicamente, los modelos de lenguaje no entienden palabras, sino números. Así, una vez tenemos el texto de entrada del modelo, hay que transformarlo en números. Para ello, cada modelo tiene una lista de todas las palabras (o tokens) que conoce, llamada vocabulario, y la entrada se corta en tokens en base a esa lista. Esto se llama tokenización.
Además, para cada token, el vocabulario contiene también un vector asociado a él, que es lo que utiliza el modelo internamente para representarlas. Si no sabéis qué es un vector, imaginad que simplemente es una lista de números, y podéis pensar que el vector es la “huella digital” de cada token.
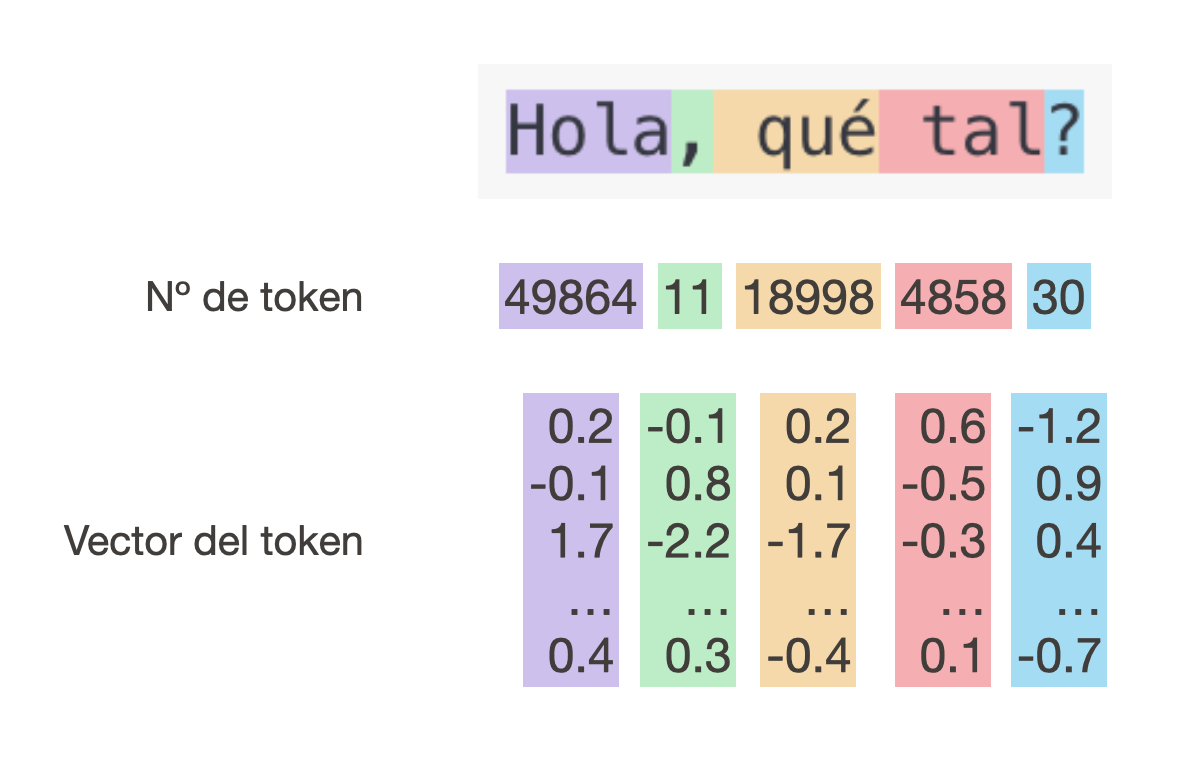
De esta manera, si, por ejemplo, la entrada contiene 100 tokens, el modelo la transforma en 100 vectores. Y si cada vector tiene, por ejemplo, 512 números, la entrada se transforma en 51.200 números.1
Generar un nuevo token
Esta parte es la más opaca de todo el proceso, a la que se suele llamar caja negra, por lo que se la suele criticar. Cada modelo tiene una cantidad de otros números, llamados parámetros, que conforman lo que sería la “huella digital” del modelo. Estos parámetros son el resultado de su entrenamiento, y no cambian salvo que se vuelva a entrenar el modelo.
Ahora tenemos, por un lado, el texto de entrada convertido a números, y, por el otro, los parámetros del modelo. Todos estos valores se combinan en millones y millones de operaciones aritméticas predefinidas, el resultado de las cuales es la lista de probabilidades de la que hablé en la publicación sobre la aleatoriedad de estos modelos. Como expliqué allí, de esas probabilidades se obtiene un nuevo token.
En nuestro ejemplo, el nuevo token sería “Estoy”.
Vuelta a empezar
Hemos explicado el proceso por el cual, para una cierta entrada, obtenemos un nuevo token. Para generar una respuesta completa, normalmente se necesita más de un token, así que lo que se hace es añadir el nuevo token a la entrada y repetir todo el proceso, tantas veces como sea necesario.
En nuestro ejemplo, eso significa que la nueva entrada será
<INICIO_DEL_TEXTO> <INICIO_ROL>sistema<FIN_ROL> Fecha de corte de entrenamiento: Diciembre 2024 Fecha de hoy: 8 Junio 2025 Eres un asistente útil. <INICIO_ROL>usuario<FIN_ROL> Hola, qué tal? <INICIO_ROL>asistente<FIN_ROL> Estoy
Repetimos el proceso y obtenemos “ muy” como nuevo token. Lo añadimos a la entrada y queda
<INICIO_DEL_TEXTO> <INICIO_ROL>sistema<FIN_ROL> Fecha de corte de entrenamiento: Diciembre 2024 Fecha de hoy: 8 Junio 2025 Eres un asistente útil. <INICIO_ROL>usuario<FIN_ROL> Hola, qué tal? <INICIO_ROL>asistente<FIN_ROL> Estoy muy
Repetimos el proceso una vez más y obtenemos el token “ bien”. Lo añadimos a la entrada:
<INICIO_DEL_TEXTO> <INICIO_ROL>sistema<FIN_ROL> Fecha de corte de entrenamiento: Diciembre 2024 Fecha de hoy: 8 Junio 2025 Eres un asistente útil. <INICIO_ROL>usuario<FIN_ROL> Hola, qué tal? <INICIO_ROL>asistente<FIN_ROL> Estoy muy bien
Repetimos una vez más y obtenemos el token “!”. La entrada queda así:
<INICIO_DEL_TEXTO> <INICIO_ROL>sistema<FIN_ROL> Fecha de corte de entrenamiento: Diciembre 2024 Fecha de hoy: 8 Junio 2025 Eres un asistente útil. <INICIO_ROL>usuario<FIN_ROL> Hola, qué tal? <INICIO_ROL>asistente<FIN_ROL> Estoy muy bien!
Volvemos a repetir el proceso y esta vez obtenemos el token “<FIN_DEL_TEXTO>”. Este es un token especial, que marca que la generación de tokens ha terminado. En este momento, la respuesta “Estoy muy bien” se considera completa, se le envía al usuario y la ejecución termina.
Conclusión
Espero que con esta explicación quede más o menos claro el proceso de interacción con un modelo de lenguaje. Ya veis que “solo” se trata de operaciones aritméticas a granel. También me gustaría que sirviera para desmitificar estos sistemas de IA, a los que, a veces, de manera consciente o inconsciente, se les atribuye consciencia, agencia o inteligencia. Unas cualidades que, hasta donde yo sé, las operaciones aritméticas no tienen. Gracias por leerme.
En realidad, a estos vectores aún hay que aplicarles una transformación para incluir su posición. Omito esto porque es un detalle técnico.